
这里是布树辉,西北工业大学的教授的个人网站。我于2006年和2009年获得了日本筑波大学的硕士和博士学位。在2009年至2011年期间,在日本京都大学担任助理教授。研究方向包括:无人机、无人系统的感知与控制,计算机视觉,机器学习。最近的活动可以在个人活动介绍里找到。
Here is Shuhui Bu’s (布树辉) personal website. Currently, I am a professor at Northwestern Polytechnical University, China. I received the MSc and PhD degrees in College of Systems and Information Engineering from University of Tsukuba, Japan in 2006 and 2009. During 2009-2011 I was an assistant professor at Kyoto University, Japan. My research interests are concentrated on perception and control of UAV, computer vision, and machine learning, and related fields. Recent activity can be found at News.
主要从事的研究方向是无人机、无人系统的环境感知,即通过计算机视觉(SLAM,SfM)构建三维场景,然后通过机器学习来实现高层语义信息的提取。研究的整体架构如下图所示:
My main research direction is environment perception for UAV, which is building three-dimensional scenes through computer vision (SLAM,SfM), and then extracting high-level semantic information through machine learning, so as to provide decision support for unmanned systems. The overall structure of the study is shown in the previous figure.
Computer vision: the main research in SLAM direction is how to solve the position and attitude of the camera in real time and reconstruct the point cloud of the scene. The main achievements include GSLAM (ICCV 2019) and SDTAM (semi-direct SLAM) method in 2016. After obtaining the local sparse point cloud, we use MapFusion to fuse the local map into a global map. The main research achievements include MapDFusion (iROS 2016), firstly proposed to use visual SLAM to generate two-dimensional map; TerrainFusion (iROS 2019), which uses visual SLAM incremently generate 2.5D map (DSM map); PointFusion (iROS 2020), real-time incremental generation dense 3D point cloud.
Machine learning direction: mainly studies scene analysis, scene recognition, target recognition, change detection and so on. The main research achievements include the scene parsing deep learning network based on adversarial learning in 2018, the analytical deep neural network based on multimodal aerial images published on PR in 2017, the scene parsing deep learning network based on integrated structure learning published by PR in 2016, and the scene recognition network based on deep learning published in Neurocomputing in 2016. Rotation-insensitive remote sensing image target recognition depth learning method published in IEEE TGRS in 2018, aerial image recognition depth learning method based on intermediate layer expression on TGRS in 2015, CRF-based multi-scale aerial image object detection depth learning method published in Neurocomputing in 2015, difference detection depth neural network for double regions of interest published on Neurocomputing in 2019, difference detection network based on Mask. In the field of 3D object recognition, the main achievements include the depth learning method of 3D object recognition based on depth confidence network published on IEEE TMM in 2014, which is the first time that the deep learning method has been introduced into the field of 3D object recognition. The paper published on IEEE MM in 2014 proposed the use of multi-modal fusion to realize 3D object recognition. A depth learning method for 3D object recognition based on local depth features published in Computer & Graphics in 2015.
Ke Li, Changqing Zou, Shuhui Bu, Yun Liang, Jian Zhang, Minglun Gong, Pattern Recognition, 2018.
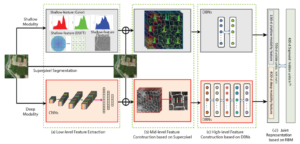
This paper presents a multi-modal feature fusion based framework to improve the geographic image annotation. To achieve effective representations of geographic images, the method leverages a low-to-high learning flow for both the deep and shallow modality features. It first extracts low-level features for each input image pixel, such as shallow modality features (SIFT, Color, and LBP) and deep modality features (CNNs). It then constructs mid-level features for each superpixel from low-level features. Finally it harvests high-level features from mid-level features by using deep belief networks (DBN). It uses a restricted Boltzmann machine (RBM) to mine deep correlations between high-level features from both shallow and deep modalities to achieve a final representation for geographic images. Comprehensive experiments show that this feature fusion based method achieves much better performances compared to traditional methods.
Shuhui Bu, Yong Zhao, Gang Wan, and Zhenbao Liu, IEEE/RSJ International Conference on Intelligent Robots and Systems, 2016.

We present a real-time approach to stitch large-scale aerial images incrementally. A monocular SLAM system is used to estimate camera position and attitude, and meanwhile 3D point cloud map is generated. When GPS information is available, the estimated trajectory is transformed to WGS84 coordinates after time synchronized automatically. Therefore, the output orthoimage retains global coordinates without ground control points. The final image is fused and visualized instantaneously with a proposed adaptive weighted multiband algorithm. To evaluate the effectiveness of the proposed method, we create a publicly available aerial image dataset with sequences of different environments. The experimental results demonstrate that our system is able to achieve high efficiency and quality compared to state-of-the-art methods. Detailed information can be accessed at http://www.adv-ci.com/blog/projects/map2dfusion/
Shuhui Bu, Yong Zhao, Gang Wan, Ke Li, Gong Cheng, Zhenbao Liu, Multimedia Tools Application, 2016.
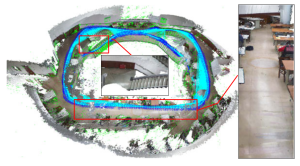
In this paper we present a novel semi-direct tracking and mapping (SDTAM) approach for RGB-D cameras which inherits the advantages of both direct and feature based methods, and consequently it achieves high efficiency, accuracy, and robustness. The input RGB-D frames are tracked with a direct method and keyframes are refined by minimizing a proposed measurement residual function which takes both geometric and depth information into account. A local optimization is performed to refine the local map while global optimization detects and corrects loops with the appearance based bag of words and a co-visibility weighted pose graph. Our method has higher accuracy on both trajectory tracking and surface reconstruction compared to state-of-the-art frame-to-frame or frame-model approaches. We test our system in challenging sequences with motion blur, fast pure rotation, and large moving objects, the results demonstrate it can still successfully obtain results with high accuracy. Furthermore, the proposed approach achieves real-time speed which only uses part of the CPU computation power, and it can be applied to embedded devices such as phones, tablets, or micro aerial vehicles (MAVs). The project website is http://www.adv-ci.com/blog/projects/sdtam/
Shuhui Bu, Pengcheng Han, Zhenbao Liu, Junwei Han, Pattern Recognition, 2016.

Effective features and graphical model are two key points for realizing high performance scene parsing. Recently, Convolutional Neural Networks (CNNs) have shown great ability of learning features and attained remarkable performance. However, most researches use CNNs and graphical model separately, and do not exploit full advantages of both methods. In order to achieve better performance, this work aims to design a novel neural network architecture called Inference Embedded Deep Networks (IEDNs), which incorporates a novel designed inference layer based on graphical model. Through the IEDNs, the network can learn hybrid features, the advantages of which are that they not only provide a powerful representation capturing hierarchical information, but also encapsulate spatial relationship information among adjacent objects. We apply the proposed networks to scene labeling, and several experiments are conducted on SIFT Flow and PASCAL VOC Dataset. The results demonstrate that the proposed IEDNs can achieve better performance.
Qin Li, Ke Li, Xiong You, Shuhui Bu, Zhenbao Liu, Neurocomputing, vol. 199, pp. 114-127, 2016.
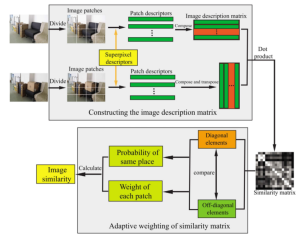
Effective features and similarity measures are two key points to achieve good performance in place recognition. In this paper we propose an image similarity measurement method based on deep learning and similarity matrix analyzing, which can be used for place recognition and infrastructure-free navigation. In order to obtain high representative feature, Convolutional Neural Networks (CNNs) are adopted to extract hierarchical information of objects in the image. In the method, the image is divided into patches, then the similarity matrix is constructed according to the patch similarities. The overall image similarity is determined by a proposed adaptive weighting scheme based on analyzing the data difference in the similarity matrix. Experimental results show that the proposed method is more robust than the existing methods, and it can effectively distinguish the different place images with similar-looking and the same place images with local changes. Furthermore, the proposed method has the capability to effectively solve the loop closure detection in Simultaneous Locations and Mapping (SLAM).
Shuhui Bu, Zhenbao Liu, Junwei Han, Jun Wu, Rongrong Ji, IEEE Transactions on Multimedia, vol. 16, no. 8, pp. 2151-2167, 2014.
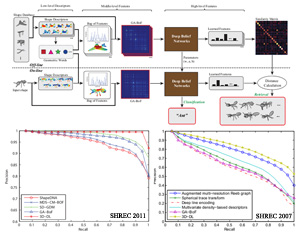
In this paper, we propose a multi-level 3D shape feature extraction framework by using deep learning. To the best of our knowledge, it is the first time to apply deep learning into 3D shape analysis. Experiments on 3D shape recognition and retrieval demonstrate the superior performance of the proposed method in comparison to the state-of-the-art methods. We implement a deep learning toolbox with GPU which can boost the computation performance greatly. The source code is publicly available and easy to use.
Shuhui Bu, Shaoguang Cheng, Zhenbao Liu, Junwei Han, IEEE Multimedia, vol. 21, no. 4, pp. 38-46, 2014.
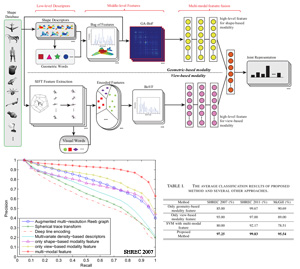
This paper presents a novel 3D feature learning framework which can combine different modality data effectively to promote the discriminability of uni-modal feature. Two independent Deep Belief Networks (DBNs) are employed to learn high-level features from low-level features, and a Restricted Boltzmann machine (RBM) is trained for mining the deep correlations between the different modalities. According to our knowledge, we are the first to introduce the multi-modal feature fusion into 3D shape analysis. We implement a deep learning toolbox with GPU which can boost the computation performance greatly. The source code is publicly available and easy to use.
Shuhui Bu, Pengcheng Han, Zhenbao Liu, Ke Li, Junwei Han, The Visual Computer, vol. 30, no. 5, pp. 867-876, 2014.
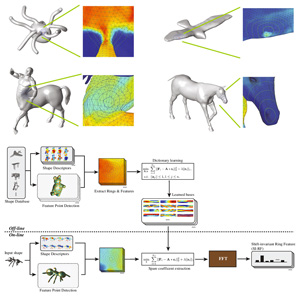
In this paper, we present a shift-invariant ring feature for 3D shape, which can encode multiple low-level descriptors and provide high-discriminative representation of local region for 3D shape. First, several iso-geodesic rings are created at equal intervals, and then low-level descriptors on the sampling rings are used to represent the property of a feature point. In order to boost the descriptive capability of raw descriptors, we formulate the unsupervised basis learn-ing into an L1-penalized optimization problem, which uses convolution operation to address the rotation ambiguity of descriptors resulting from different starting points in rings. In the following extraction procedure of high-level feature, we use the learned bases to calculate the sparse coefficients by solving the optimization problem. Furthermore, to make the coefficients irrelevant with the sequential order in ring, we use Fourier transform to achieve circular-shift invariant ring feature. Experiments on 3D shape correspondence and retrieval demonstrate the satisfactory performance of the pro-posed intrinsic feature.
Zhenbao Liu, Sicong Tang, Weiwei Xu, Shuhui Bu, Junwei Han, Kun Zhou, Computer Graphics Forum, vol. 33, no. 7, 2014.
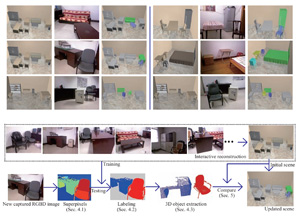
Since indoor scenes are frequently changed in daily life, such as re-layout of furniture, the 3D reconstructions for them should be flexible and easy to update. We present an automatic 3D scene update algorithm to indoor scenes by capturing scene variation with RGBD cameras. We assume an initial scene has been reconstructed in advance in manual or other semi-automatic way before the change, and automatically update the reconstruction according to the newly captured RGBD images of the real scene update. It starts with an automatic segmentation process without manual interaction, which benefits from accurate labeling training from the initial 3D scene. After the segmentation, objects captured by RGBD camera are extracted to form a local updated scene. We formulate an optimization problem to compare to the initial scene to locate moved objects. The moved objects are then integrated with static objects in the initial scene to generate a new 3D scene. We demonstrate the efficiency and robustness of our approach by updating the 3D scene of several real-world scenes.
Zhizhong Han, Zhenbao Liu, Junwei Han, Shuhui Bu, The Visual Computer, vol. 30, no. 7, 2014.
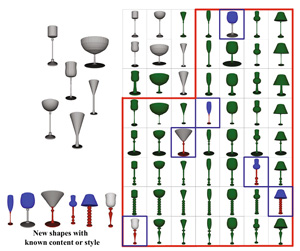
In this paper, we propose a new style transfer method for automatic 3D shape creation based on new concepts of style and content of 3D shapes. Our unsupervised style transfer method could plausibly create novel shapes not only by recombining existent styles and contents in a set but also by combining new-coming styles or contents with the existent ones conveniently. This feature provides a better way to increase the diversity of created shapes. We test our method in several sets of man-made 3D shapes and obtain plausible created shapes based on the reasonably separated styles and contents.
D. Pickup, X. Sun, P.L. Rosin, R.R. Martin, Z. Cheng, Z. Lian, M. Aono, A. Ben Hamza, A. Bronstein, M. Bronstein, S. Bu, U. Castellani, S. Cheng, V. Garro, A. Giachetti, A. Godil, J. Han, H. Johan, L. Lai, B. Li, C. Li, H. Li, R. Litman, X. Liu, Z. Liu, Y. Lu, A. Tatsuma, J. Ye, Eurographics Workshop on 3D Object Retrieval, 2014.

SHREC’14 is a new benchmarking dataset for testing non-rigid 3D shape retrieval algorithms, one that is much more challenging than existing datasets. The dataset features exclusively human models, in a variety of body shapes and poses. 3D models of humans are commonly used within computer graphics and vision, and so the ability to distinguish between body shapes is an important shape retrieval problem. Our deep learning method is test on this dataset, and achieve good results.
Junwei Han, Peicheng Zhou, Dingwen Zhang, Gong Cheng, Lei Guo, Zhenbao Liu, Shuhui Bu, Jun Wu, ISPRS Journal of Photogrammetry and Remote Sensing, vol. 89, no. 3, pp. 37-48, 2014.

Automatic detection of geospatial targets in cluttered scenes is a profound challenge in the field of aerial and satellite image analysis. In this paper, we propose a novel practical framework enabling efficient and simultaneous detection of multi-class geospatial targets in remote sensing images (RSI) by the integra-tion of visual saliency modeling and the discriminative learning of sparse coding. Comprehensive evaluations on a satellite RSI data-base and comparisons with a number of state-of-the-art approaches demonstrate the effectiveness and efficiency of the proposed work.
Chengliang Li, Zhongsheng Wang, Shuhui Bu, Hongkai Jiang, and Zhenbao Liu, Journal of Mechanical engineering Science, vol. 228, no. 6, pp. 1048-1062, 2014.
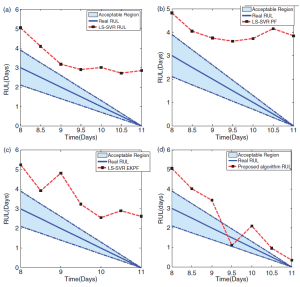
This paper presents a novel method for machinery condition prognosis, named least squares support vector regression strong tracking particle filter which is based on least squares support vector regression combing with strong tracking particle filter. There are two main contributions in our work: first, the regression function of least squares support vector regression is extended, which constructs a bridge for the application of combining data-driven method with a recursive filter based on extend Kalman filter; second, an extend Kalman filter-based particle filter is studied by introducing a strong tracking filter into a particle filter. The experiment results demonstrate that the proposed method is better than classical condition predictors in machinery condition prognosis.
Shuhui Bu, Zhenbao Liu, Tsuyoshi Shiina, Kengo Kondo, Makoto Yamakawa, Kazuhiko Fukutani, Yasuhiro Sommeda, and Yasufumi Asao, IEEE Transactions on Biomedical Engineering, vol. 59, no.5, pp.1354-1363, 2012.
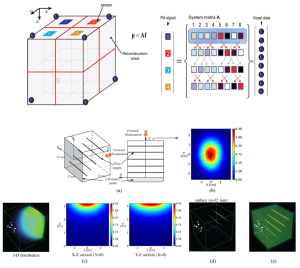
This paper introduces a reconstruction method for reducing amplification of noise and artifacts in lowfluence regions. In this method, fluence compensation is integrated into model-based reconstruction, and the absorption distribution is iteratively updated. At each iteration, we calculate the residual between detected PAsignals and the signals computed by a forward model using the initial pressure, which is the product of estimated voxel value and light fluence. By minimizing the residual, the reconstructed values converge to the true absorption distribution. In addition, we developed a matrix compression method for reducing memory requirements and accelerating reconstruction speed. The results of simulation and phantom experiments indicate that the proposed method provides a better contrast-to-noise ratio (CNR) in low-fluence regions. We expect that the capability of increasing imaging depth will broaden the clinical applications of PAT.
Bunichiro Shibazaki, Shuhui Bu, Takanori Matsuzawa, and Hitoshi Hirose, Journal of Geophysical Research, vol. 115, B00A19, Apr. 2010.
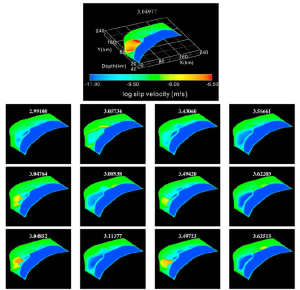
We developed a model of short‐term slow slip events (SSEs) on the 3‐D subduction interface beneath Shikoku, southwest Japan, considering a rate‐ and state‐dependent friction law with a small cutoff velocity for the evolution effect. We assume low effective normal stress and small critical displacement at the SSE zone. On the basis of the hypocentral distribution of low‐frequency tremors, we set three SSE generation segments: a large segment beneath western Shikoku and two smaller segments beneath central and eastern Shikoku. Using this model, we reproduce events beneath western Shikoku with longer lengths in the along‐strike direction and with longer recurrence times compared with events beneath central and eastern Shikoku. The numerical results are consistent with observations in that the events at longer segments have longer recurrence intervals.
更多发表论文信息可以参阅 《发表论文列表》。
Full publication list can be found at here.